TYPES OF MACHINE LEARNING

Machine learning is a subset of AI that enables the machine to automatically learn from data, improve performance from past experiences, and make predictions. Machine learning is a set of algorithms that work on a huge amount of data. Data is fed to these algorithms to train them, and on the basis of training, they build the model and perform a specific task.
Why is ML useful?
We can use ML algorithms to solve and improve an infinite number of tasks. For example, predicting whether a bank client is going to pay back a credit or not; when an engine is about to break; or knowing the type of a plant based on its features. Every task will be solved using different algorithms and techniques.
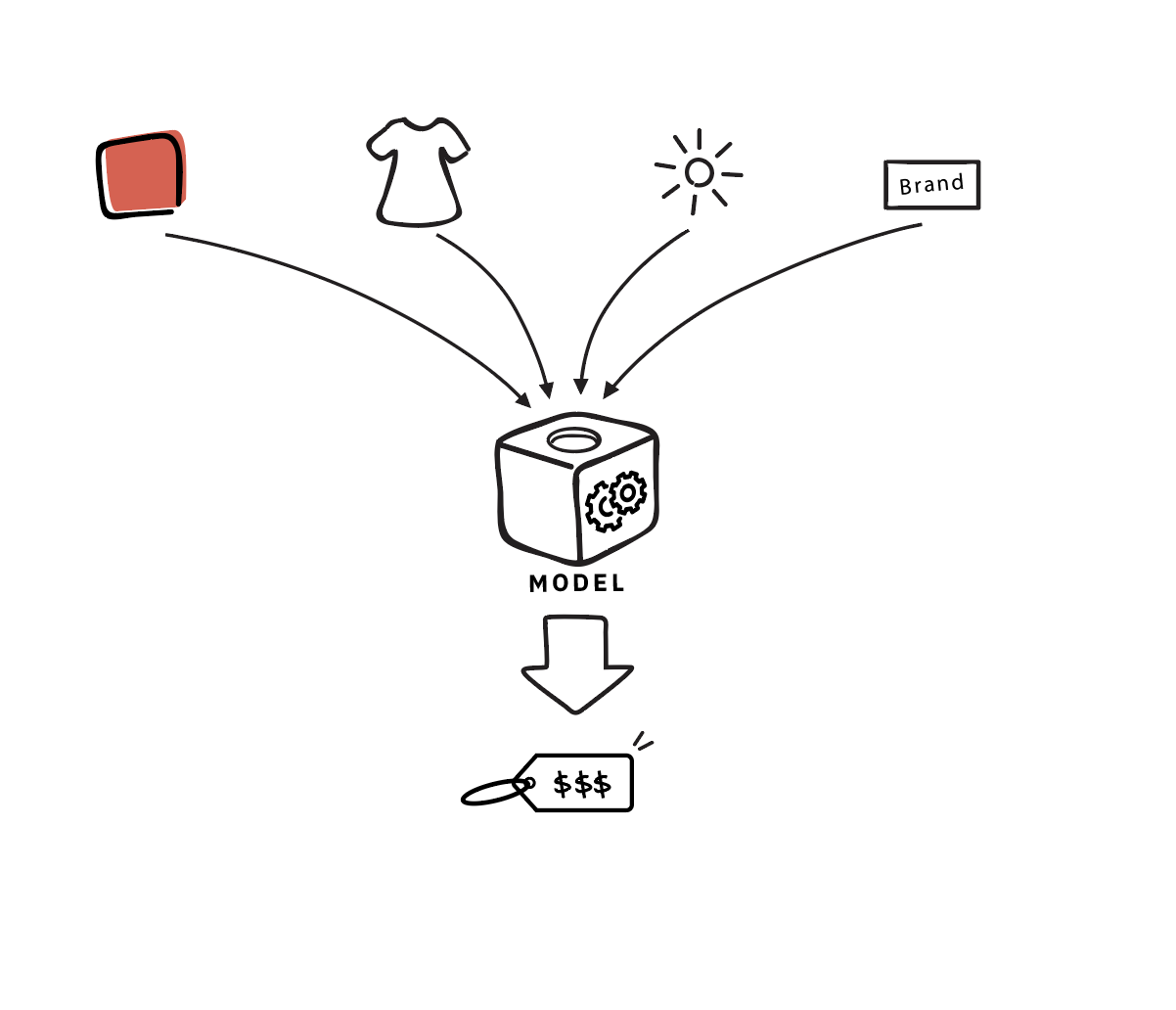
Types of Machine Learning
I'm going to focus on the two main types: supervised and unsupervised learning.
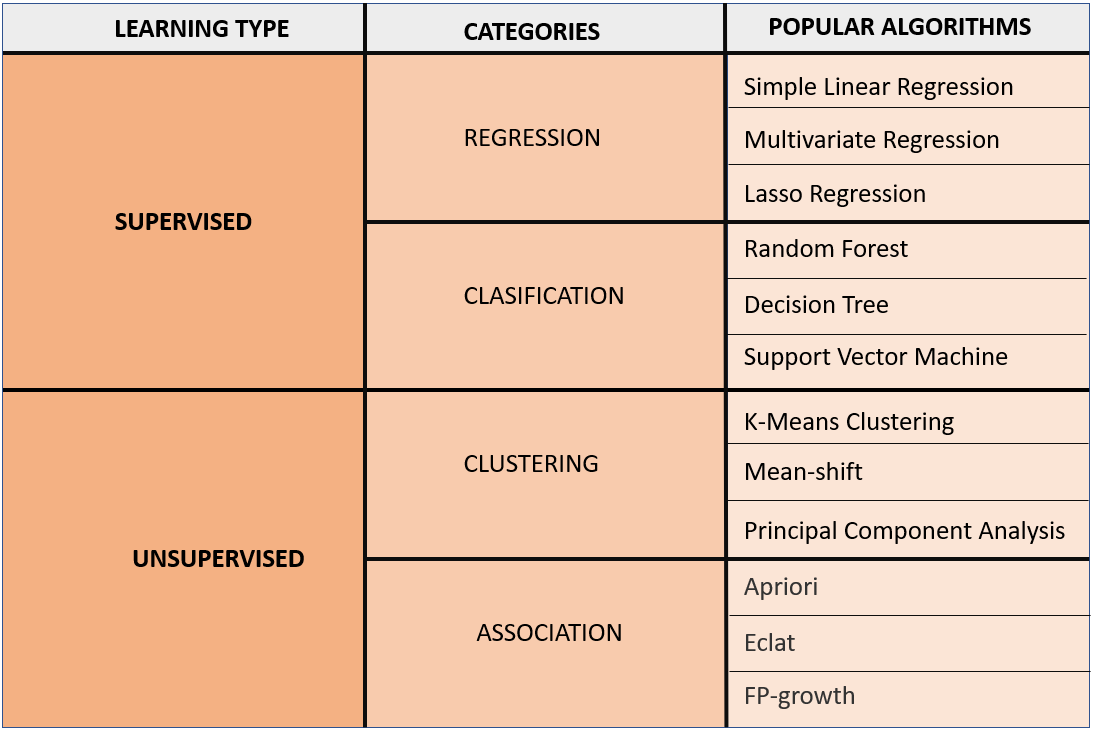
However, they are more types, these are, Semi-Supervised Learning and Reinforcement Learning.
1.- Supervised Learning
As the name suggests, the output of the model created is supervised. We train the machine using labelled data. This is, we use the labelled data to train a model. Once the algorithm is fitted, we test it. This is, we predict the output data of some input data. This way, we can evaluate the performance of the model. We can do this since we know what the output for each input is.
However, consider this two problems:
- You want to know whether a patient suffer from a disease or not, based on the quantity of gene 1 and gene 2 in her body.
- Make a model that predicts a patient's lifespan based on the amount of gene 1 present in her body.
In the first case, the output will be a class, a type. In this case, there are two options: whether you have a disease or not, true or false, two classes. On the other hand, in the second case, the goal is to estimate a number. Therefore, we have two types of supervised categories of machine learning.
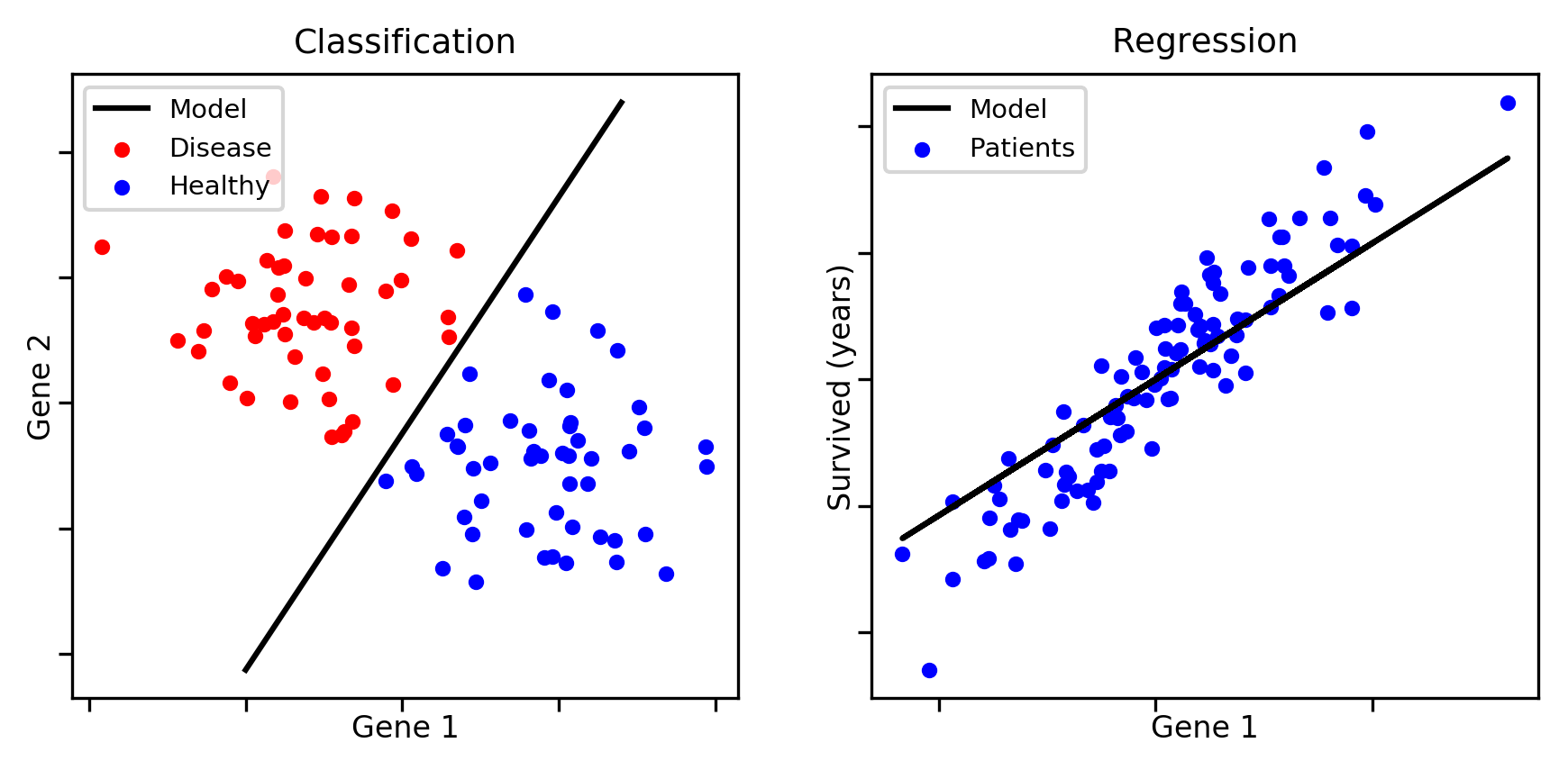
Classification:
The output is categorical, a class. Yes or no, the type of animal or the colour, spam or not…. It depends on the problem.
Some popular classification algorithms are: Random forest, Decision Tree, Logistic Regression Algorithm and Support vector Machine Algorithm. Some of these will be explain in this blog later on.
Regression:
Regression algorithms are used when a linear relationship between inputs and outputs exists. They are used to make continuous predictions. Some examples: predict temperature, salary, markets trends….
The most famous algorithms are: Simple Linear Regression Algorithm and Multivariate regression Algorithm .
2.- Unsupervised Learning
Humans can learn in a variety of ways. Going to school and learning from our teacher will be the closest thing to supervised learning. In this instance, the teacher will oversee your assignment and show you the solutions. You are the one who needs to acquire that knowledge.

However, this isn't the only way we can learn. I can show two pictures to a kid, one of an elephant and another of a dog, and he will know that those are not the same animal. Another example is that one can learn the rules of a new game without anyone telling him what they are, just by observing. This is unsupervised learning. In this case there is no supervision. This is, the model is train using a unlabelled dataset.
The unsupervised learning algorithms primary goal is to classify or group the unsorted dataset based on commonalities, patterns, and differences. The hidden patterns in the input dataset are to be found by the machines.
When we use supervised learning, we know the classes. When we use unsupervised learning, we want to discover insights in the data, how the algorithm think is the best way to group the data.
The categories of Unsupervised Learning are Clustering and Association.
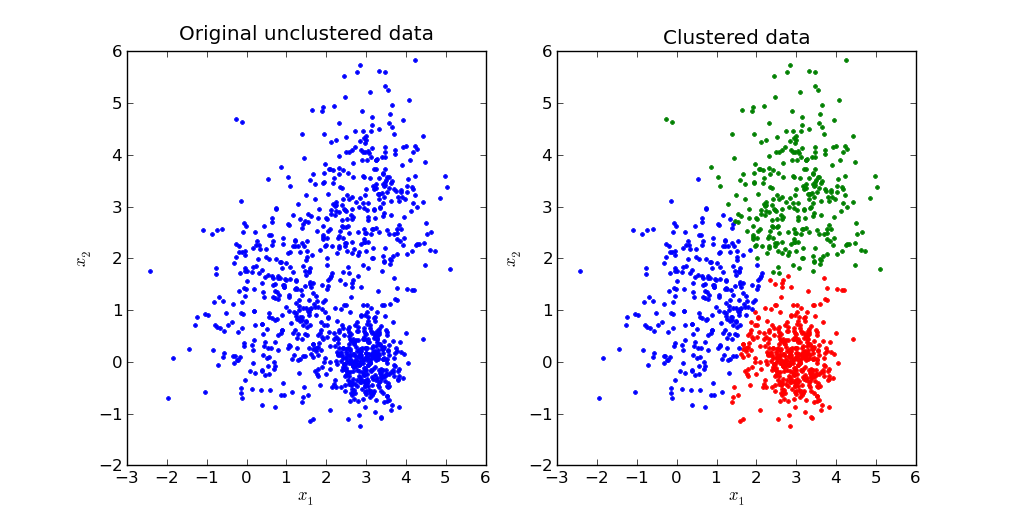
1: Clustering
As its name suggests, this method groups data points into clusters based on the similarities between their features.
Clustering is frequently used by retail businesses to find groups of homes that are similar to one another. For instance, a retailer may compile the household data listed below:
- Household income
- Household size
- Head of household Occupation
- Distance from nearest urban area
This data can be used to build a clustering algorithm. In this case, 4 clusters may be found.
- Small family, high spenders
- Larger family, high spenders
- Small family, low spenders
- Large family, low spenders
This way, the company can use these insights to use direct marking and improve the performance in sales with a decrease in marketing.
The most used clustering algorithms are: K-means, PCA and Independent component analysis.
2: Association
This unsupervised learning method is call association learning and it identifies intriguing relationships between variables in a large dataset. This learning algorithm's primary goal is to identify the dependencies between data items and then map the variables in a way that maximizes profit. This method is mostly used in continuous production, web usage mining, market basket analysis, etc.
Apriori, Eclat, and FP-growth algorithms are a few of the well-known algorithms for learning association rules.